크롤링할때마다 사용하는 파이썬 셀레니움 패키지 (python selenium)
그중 가장 많이 사용하는 함수인 find_elemnt_by_, find_elements_by_ 사용법에 대해서 간단히 정리하고자 한다.
find_element_by, find_elements_by 차이점은?
find_element_by와 find_elements_by은 동일한 동작을 하지만, 아래와 같은 차이가 있다.
- element 는 조건에 일치하는 가장 첫번째 요소를 반환
- elements는 조건에 일치하는 모든 요소를 list 형태로 반환
즉, 한개만 return하냐, 모든 요소를 return 하냐의 차이다.
보통 해당 페이지에 조건에 만족하는 element가 유일하다는게 보장된다면 find_element_by를,
list중에서 한번 더 필터링을 거쳐서 찾아야 하거나, 해당 list 모두가 필요할 경우에는 find_elements_by를 사용한다.
파이썬 셀레니움에서 지원하는 find_element_by, find_elements_by
selenium의 webdriver에서 지원하는 find_elements_by_ 는 아래와 같다.
각 함수의 사용방법에 대해서 알아보자 (동작원리는 동일하기 때문에 편의상 find_elements_by 만 설명한다)
- find_elements_by_tag_name
- find_elements_by_xpath
- find_elements_by_id
- find_elements_by_class_name
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_css_selector
크롤링을 해보자
크롤링 대상이 되는 element는 아래와 같다. 네이버 초기화면 중에서 "네이버를 시작페이지로" 라고 표시된 부분이다.
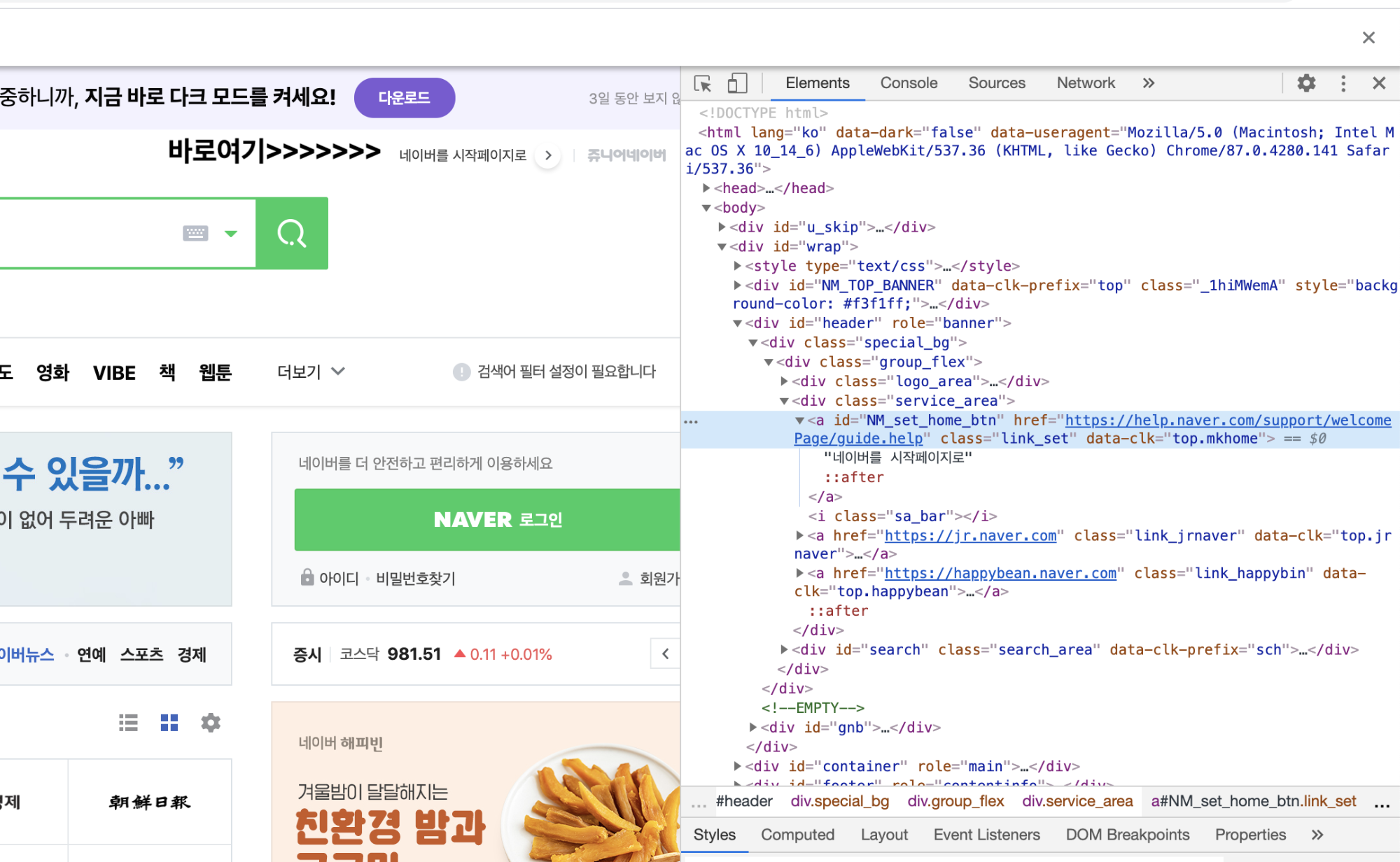
크롬 개발자 도구를 통해서 해당 element의 값을 확인해보자.
다양한 방식으로 element값을 copy 할수 있는데, element위에서 마우스 오른쪽을 클릭하면 아래와 같은 메뉴가 나온다.

각 메뉴의 결과를 확인해보자. 아래는 해당 메뉴에 대한 copy 결과 값이다. (본 포스팅의 글과 상관없는 메뉴는 제외했다.)
## Copy Element
<a id="NM_set_home_btn" href="https://help.naver.com/support/welcomePage/guide.help" class="link_set" data-clk="top.mkhome">네이버를 시작페이지로</a>
## Copy selector
#NM_set_home_btn
##Copy XPath
//*[@id="NM_set_home_btn"]
## Copy full XPath
/html/body/div[2]/div[2]/div[1]/div/div[2]/a[1]find_elements_by 결과 확인하기
그러면, 이제 find_elements_by 함수를 사용해서 크롤링 해보자.
크롤링 코드는 아래와 같다.
from selenium import webdriver
driver = webdriver.Chrome("chromedriver")
driver.get("https://www.naver.com")
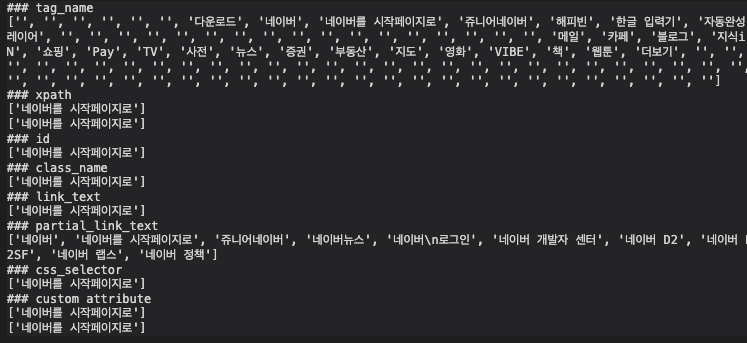
print("### tag_name")
print([e.text for e in driver.find_elements_by_tag_name('a')[:100] if 'text' in dir(e)])
print("### xpath")
print([e.text for e in driver.find_elements_by_xpath('//*[@id="NM_set_home_btn"]')])
print([e.text for e in driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[1]/div/div[2]/a[1]')])
print("### id")
print([e.text for e in driver.find_elements_by_id("NM_set_home_btn")])
print("### class_name")
print([e.text for e in driver.find_elements_by_class_name("link_set")])
print("### link_text")
print([e.text for e in driver.find_elements_by_link_text("네이버를 시작페이지로")])
print("### partial_link_text")
print([e.text for e in driver.find_elements_by_partial_link_text("네이버")])
print("### css_selector")
print([e.text for e in driver.find_elements_by_css_selector("#NM_set_home_btn")])
print("### custom attribute")
print([e.text for e in driver.find_elements_by_css_selector("[data-clk='top.mkhome']")])
print([e.text for e in driver.find_elements_by_xpath("//*[@data-clk='top.mkhome']")])
각 find_elements_by를 자세히 보면 사용된 인자들이 다르다.
element를 copy한 결과와 비교하면 다음과 같다.
- find_elements_by_tag_name: Copy Element의 tag
- find_elements_by_xpath: Copy XPath 또는 Copy full XPath
- find_elements_by_id: Copy Element의 id attribute
- find_elements_by_class_name: Copy Element의 class attribute
- find_elements_by_link_text: Copy Element의 text
- find_elements_by_partial_link_text: Copy Element의 text중 일부
- find_elements_by_css_selector: Copy selector
아래는 출력 결과이다.
일단 find_elements_by를 사용했기 때문에 모든 결과가 list 이다.
조건에 일치하는게 1개라면 1개만 출력되지만, 다수라면 그 모두가 출력된다. (특히 tag_name과 partial_link_text)
Custome Attribute
그렇다면, element가 아래처럼 있을때,
find_element_by에서 지원하지 않는 attribute를 기준으로 찾고자 할때는 어떻게 할까? (예를들면 오른쪽 끝, data-clk 같은..)
<a id="NM_set_home_btn" href="https://help.naver.com/support/welcomePage/guide.help" class="link_set" data-clk="top.mkhome">네이버를 시작페이지로</a>find_elements_by_css_selector, find_elements_by_xpath를 통해서 찾을수 있다 (위 크롤링 코드 참고)
'IT > Python' 카테고리의 다른 글
| python 가상환경 관리도구 pyenv 사용법 (0) | 2025.06.11 |
|---|---|
| 파이썬 assert, raise 차이점 (2) | 2021.01.12 |
| pandas itertuples, iterrows 성능 및 사용법 비교 (0) | 2020.11.27 |